-
Hyperparameter optimization _ 하이퍼파라미터 최적화Statistics 2021. 2. 25. 00:00
1. Hyperparameter
2. Grid Search와 Random Search
3. Bayesian Optimization
4. Genetic Algorithm
5. 그 외의 것들
1. Hyperparameter
흔히 통계를 배울 때, Parameter라는 말을 정말 많이 듣게 된다. 관심을 갖는 모집단의 특징, 예를 들어 모집단의 평균이나, 표준편차, 또는 선형회귀의 회귀 계수 등을 보통 Parameter라고 하는데 이와 다르게 예측 모델 등에 있어서의 Hyperparameter란 n_estimator나 learning_rate 등과 같이 사용자가 학습에 앞서 세팅해주는 값이다.
한마디로, Parameter는 모델이 알아서 정하는 값 혹은 자동적으로 얻어지는 값이고, Hyperparameter는 모델에서 실험자가 직접 정할 수 있는 값이라고 말할 수 있을 것이다.
같은 Random Forest 모델을 세운다고 해도, 트리의 깊이나 갯수, 각종 규제 등의 Hyperparameter가 다르다면 결정적인 부분에서 차이가 나게 된다. 경험상으로도 최적화가 소홀하면, 모형에 있어 언더피팅이나 오버피팅 등의 문제가 생길 우려가 높아진다. 데이터셋에 맞는 좋은 모델을 고르는 것만큼, 적합한 Hyperparameter의 집합을 찾는 것 또한 중요한 문제이다.
사실 Hyperparameter를 최적화하는 방법으로, 얼마 전 까지는 Grid Search만 사용하곤 했었다. 가장 직관적이고, 이해할 것이 적은 쉬운 방법이기 때문이다. 하지만 모델이 복잡해지거나 조정하고자 하는 Hyperparameter가 많아지면 많아질수록 (특히 학습률이나 샘플링 비율처럼 정수가 아닌 Hyperparameter를 다뤄야 할 때가,,,) 무식하게 다 돌려버리는 Grid Search는 시간도 정말 오래 걸리고, 오래 걸리는 시간 대비 효율도 별로였다. Hyperparameter Optimization에 대한 공부가 부족하여 쓸데없이 오랜 시간을 낭비했던 것이었다. 전기세 아깝게,,,
2. Grid Search와 Random Search
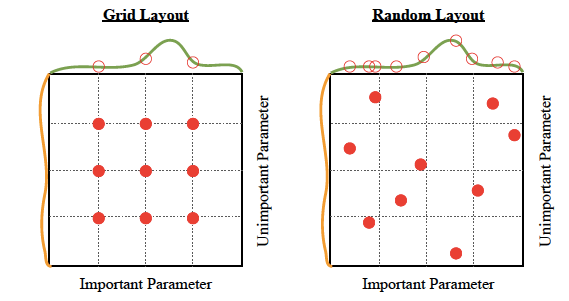
"What is the difference between parameter and hyperparameter?", neptune.ai Grid Search는 "격자" 라는 이름 뜻처럼, Hyperparameter들의 범위에 대해 가능한 모든 Point를 전부 조사하여 모델의 평가가 가장 좋은 최적의 집합을 찾아내는 것이다.
예를 들어, Hyperparameter의 범위가 A=[7, 8, 9], B=[0.05, 0.01, 0.005], C=[10, 20, 30] 라고 하면, Hyperparameter {A, B, C}에 대해 각 3가지씩 총 27가지의 경우를 모두 testing 해보는 것이다. 모델의 평가는 기본적으로 validation set이나, Cross Validation 등을 이용한다.
이러한 Grid Search는 최적화가 범위 내에서 균등하고 전역적으로 일어난다는 장점이 있지만 Hyperparameter의 가능한 경우가 매우 많거나, 고려할 Hyperparameter의 종류가 많으면 경우의 수는 곱의 법칙에 의해 기하급수적으로 늘어나게 된다. 물론 생각할 것이 많을수록 오랜 시간이 걸리는 것은 당연한 일이다. 진짜 문제점은, 오랜 시간을 들인다고 해도, 위의 그림처럼 최적화도 제대로 시키지 못할 수 있다는 문제점이 있다. 즉, 효율이 별로다.
이처럼 비효율적이라는 단점을 극복하기 위해, Grid Search를 보다 효율적으로 사용하는 방법은 Model과 Data, 그리고 Hyperparameter에 대한 이론적인 기반과 경험 하에 사전적으로 Searching의 범위를 줄여보거나, 중요도가 높은 것부터 낮은 것 까지, 혹은 넓은 범위에서 좁은 범위까지, 여러 번에 걸쳐 실행해볼 것을 이야기 해볼 수 있을 것이다. 혹은 독립적인 연산이므로 병렬 처리를 통해 빠르게 처리할 수도 있을 것이다.
Grid Search와 가장 비슷한 방법인 Random Search는, 모든 격자점에 대한 testing 대신 사전적으로 주어진 범위 하에서 랜덤으로 뽑아 testing을 하는 방식이다. 거의 모든 경우에서 Grid Search에 비해 시간을 아낄 수 있고, Hyperparameter가 연속적인 범위의 형태이거나 Grid Search로는 모든 집합을 고려하기 힘들 경우에, 보다 더 효율적이다. 위의 그림과 같이 Grid Search에 비해 더 좋은 결과를 얻어낼 수도 있을 것이다. Grid Search는 연속적인 범위를 갖는 Hyperparameter에 대해 임의로 정한 몇 가지 경우에 대해서만 고려할 수 있었기 때문이다. Random Search는 최적에 가까운 경우를 탐색할 수 있는 기회를 확률적으로 얻을 수 있기에, 결과도 Grid Search보다 좋을 수 있는 것이다.
또한, Grid Search와 비슷한 방식이기 때문에, 앞서 언급한 사전 지식의 활용과 다회에 걸친 Searching을 진행한다면 더욱 효율적인 활용이 가능할 것이다.
다양한 연구와 경험에서 이야기하듯, Random Search는 Grid Search만큼 간단하지만 훨씬 효율적인 최적화 방법이다. 하지만, 뭔가 비효율적이라는 느낌을 지울 수가 없다. Grid Search든 Random Search든 백번, 천 번을 testing 한다고 해서 그것들이 모두 의미 있는 testing이었다고 이야기하기에는 무리가 있어보인다.
그렇다면, 최적의 Hyperparameter를 찾는 방법이 과연 각 집합에 대해 일일이 독립적인 testing을 진행하는 방법만 있는 걸까?
3. Bayesian Optimization
Bayesian Optimization은 앞서 이야기한 Grid Search나 Random Search와 차이가 꽤 있는 Optimization 방식이다. 앞서 설명한 방식들은 모두 독립적인 testing의 반복을 통해 최고의 평가를 받는 모델을 선정하였던 것이라면, Bayesian Optimization은 전 단계에서 진행한 testing에서 얻어낸 사전 지식을 통해, 최적의 조합이 있을 것으로 예측되는 지점을 조사하는 방식을 반복하여 Hyperparameter의 이상적인 집합을 찾는 방식이다.
$$\underset{x \in X}{\operatorname{argmax}} {f(x)}$$
기본적으로 Bayesian Optimization은, 위와 같은 전형적인 최적화 수식을 푸는 과정이라고 볼 수 있다. X는 최적화 대상인 Hyperparameter의 범위이고, 함수 f(x)는 어떠한 Hyperparameter의 조합 x를 적용한 모델의 평가를 이야기할 것이다. 평가 척도의 경우에 따라 최대화하는 과정이 될 수도, 최소화하는 과정이 될 수도 있겠다.
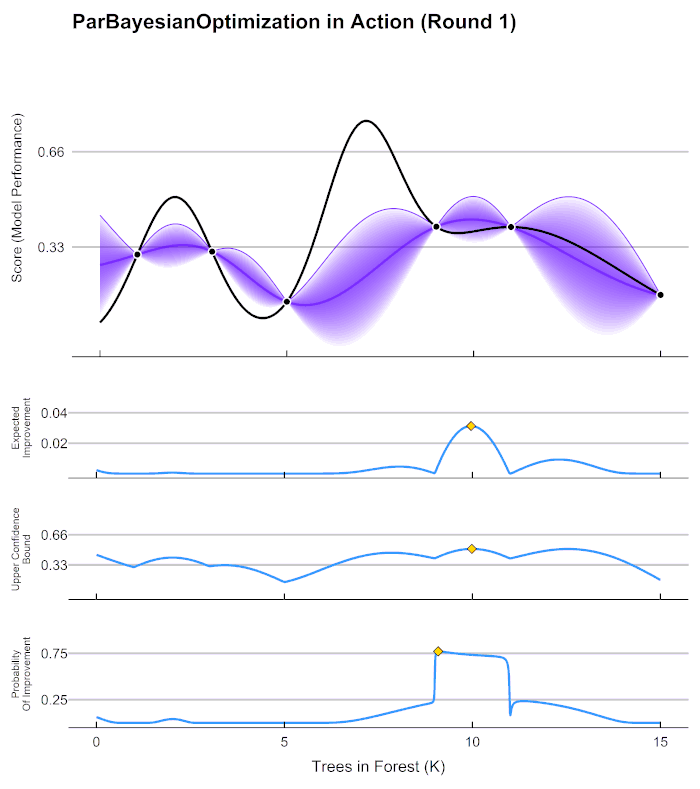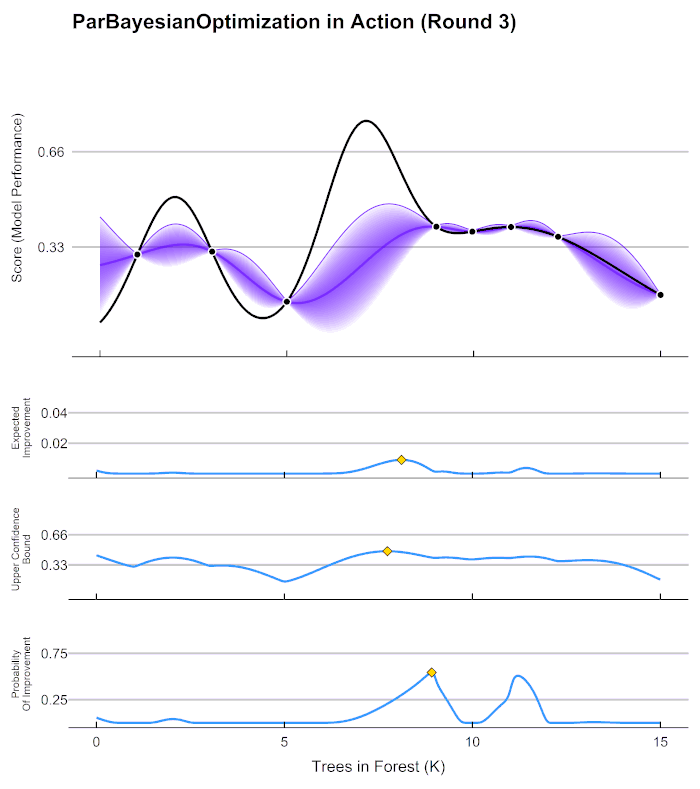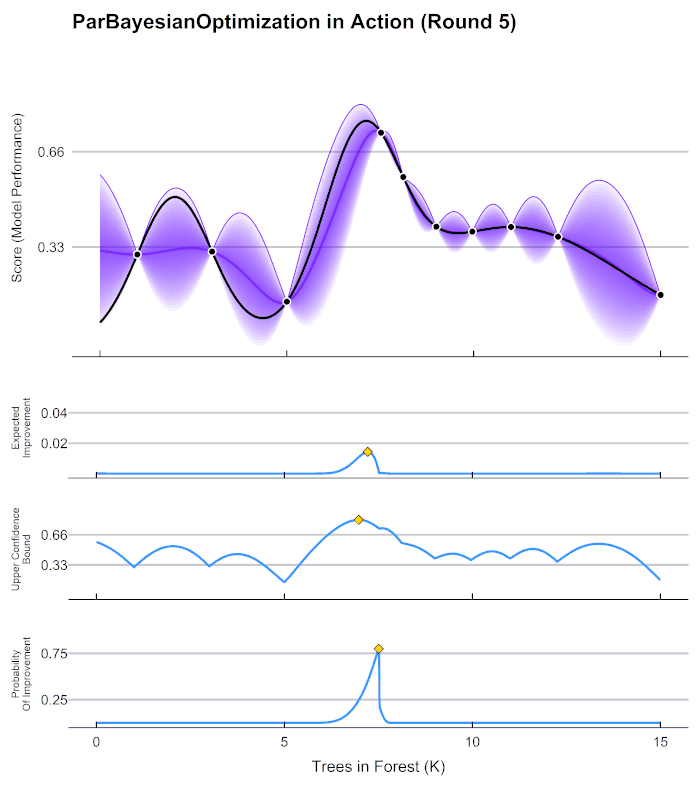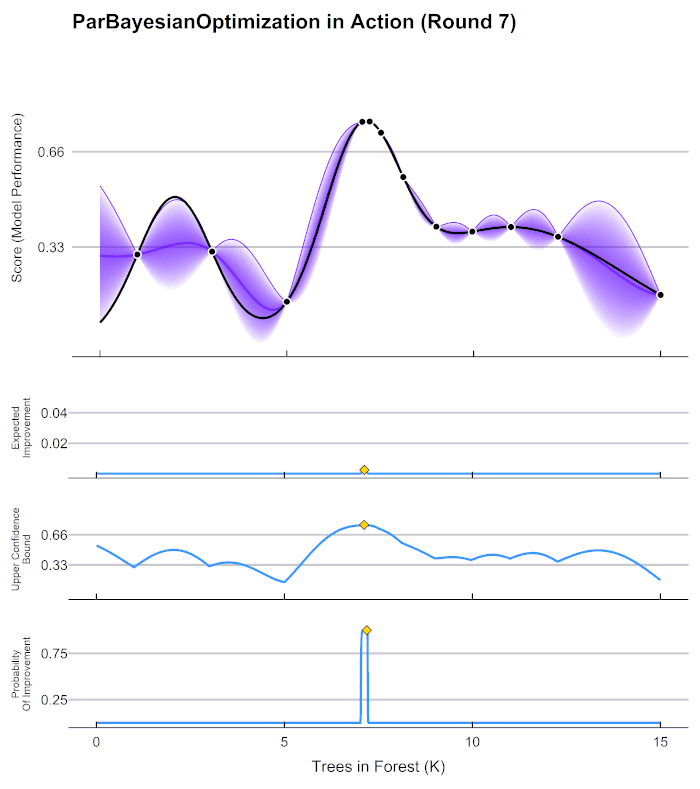
https://en.wikipedia.org/wiki/Bayesian_optimization 이후의, 좀 더 구체적인, Bayesian Optimization의 원리를 설명하는 좋은 gif가 있길래 가져왔다. 맨 위의 그래프에서, 검정 실선은 찾고자 하는 f(x)의 그래프이며, f(x)를 최대로 하는 점 x는 우리가 찾길 원하는 최적의 Hyperparameter의 조합이다. 보라색 실선은 초기의 관측값을 통해 예상되는 f(x)의 점추정치이며 보라색 영역은 범위추정치이다.
아래의 세 가지 파란 그래프는, 다음으로 관측할 점을 추천해주는 function이다. 추천 함수는 주어진 초기의 testing 결과로 얻어진 예측 함수를 보고, 최적화를 하는 데에 가장 도움이 될 것으로 생각되는 점을 다음 단계에서 testing 해보라고 추천한다. 해당 점에 대해서 testing을 했다면, 그것을 반영함으로써 예측 함수는 예측의 대상인 f(x)에 가까워지게 된다. 이러한 과정의 반복을 통해 f(x)와 거의 유사한 함수를 예측한다면, 모델을 최적화시켜주는 Hyperparameter를 찾는 것은 어렵지 않은 일이 되는 것이다. 위 그림의 세 가지의 추천 함수에 대해서는 (사실 세 가지 외에도 더 있다,,) 다음에 논문을 읽고 더 자세히 알아보아야겠다.
요약하자면, 순서는 다음과 같다.
1. 초기 testing을 통해서 f(x)에 대한 예측 함수를 만든다.
2. 다음으로 관측할 만한 점을 추천 함수로부터 추천을 받아, testing을 한다.
3. testing 한 점을 반영하여 예측 함수를 갱신한다.
4. 2 ~ 3을 반복하여 f(x)를 최대화(혹은 최소화) 시켜주는 최적의 Hyperparameter를 얻어낸다.
Snoek, Larochelle, & Adams (2012)에서는 Bayesian Optimization 자체에서 사용할 Hyperparameter의 선정 방식이 명확치 않다는 점, 병렬처리가 불가능한 점 등의 이유 때문에 실용성에 의문이 제시된다고 이야기하기도 한다. 그럼에도, Bayesian Optimization은 꽤나 똑똑한 방식으로 보인다. 매 단계의 testing이, 최적의 Hyperparameter를 찾는데 유용하기 때문이다.
4. Genetic Algorithm
Genetic Algorithm은 적자생존 이론과 유전적 다양성, 돌연변이 등의 생명체의 유전적 특징들을 반영한 최적화 방식이다. 어떤 연구에서는 Genetic Algorithm을 이용해서 Hyperparameter의 최적 조합을 찾아내기도 하였다.

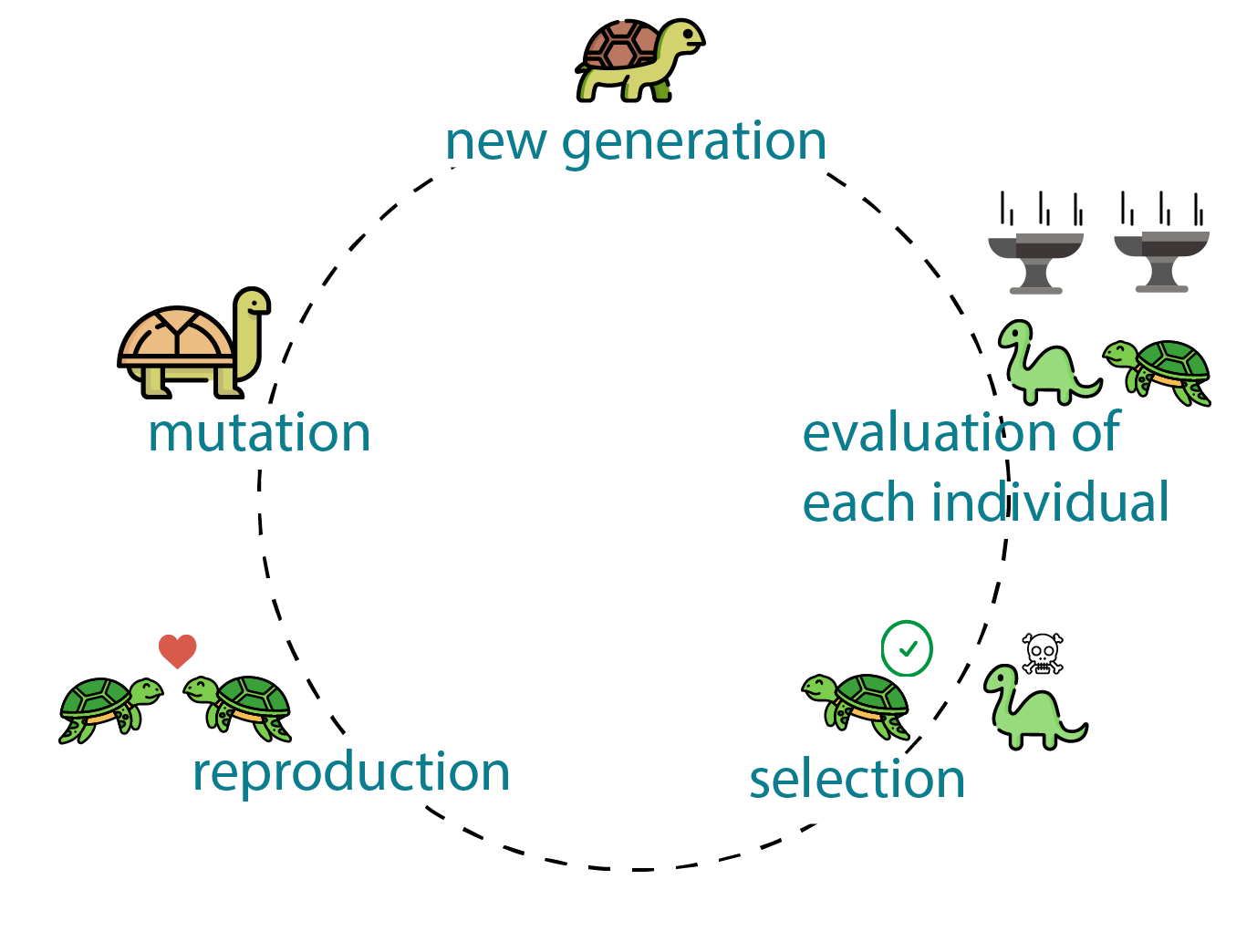
"What is Genetic Algorithm?", generativedesign.org Genetic Algorithm에서 '유전자'는 Hyperparameter의 어떤 한 조합을 의미하고, 랜덤 하게 만들어진 초기의 유전자들은 적자생존과 교배를 통해 특징을 물려받게 된다.
생물의 유전도 그렇듯, 우수한 형질을 가진 편인 세대의 자손이라고 해서 반드시 우수한 형질만을 물려받지는 않지만, 이전 세대의 특징이 우수하면 우수할수록 자손 또한 우수할 확률이 높다. 그렇기 때문에 교배의 대상은 항상 적자생존을 통해 이루어지며, 일반적인 방법으로 우수한 유전자는 확률적으로 교배의 기회를 더 많이 갖는다. 다만 우수하지 못한 유전자라고 하여 Drop 시키지는 않는데, 이는 실제 생태계의 유전적 다양성을 반영한 것으로, 알고리즘 자체가 과도하게 경직된 방향으로만 단순하게 흘러가는 것을 막음으로써 Local maximum(혹은 Local minimum)에 갇히는 것을 방지한다.
Local maximum에 갖히는 것을 방지하는 대책으로 또 하나는, 앞서 언급한 돌연변이의 존재이다. Genetic Algorithm에서는 실제 유전적 다양성에 영향을 미치는 요인 중 하나인 변이를 일정 확률로 데이터에 왜곡을 주는 특정 연산을 실행하는 방식으로 만들어낸다. 이를 반복하여 진행하면, 최적의 Hyperparameter의 조합을 찾아낼 수 있게 된다.
기본적인 Genetic Algorithm의 흐름은 위와 같다. 자세한 내용이나, ACO, SA 등의 연관된 기법들에 대해서는 나중에 공부해보아야겠다. 최적화를 실제 자연의 원리를 통해 이루어 냈다는 것이, 꽤 흥미로운 점이다.
5. 그 외의 것들
특정 모델의 경우에 한정하여, Hyperparameter에 대한 기울기를 계산한 후에 경사하강법을 통해 최적화시키는 Gradient Based Optimization이라는 방법을 사용할 수 있다고 한다.
Population Based Training이라는 방식도 있다. Genetic Algorithm을 기반으로 하는 방식으로, 서로 다른 Hyperparameter 조합을 갖는 여러 개의 모델을 독립적으로 작동시키고, 성능이 낮은 모델은 좋은 성능을 기반으로 수정된 모델로 계속해서 대체한다. 그 과정에서, 조합을 새로 뽑거나 연산을 통해 탐색을 이어나간다. 이를 반복함으로써 Model Selection과 Hyperparameter Optimization을 동시에 진행한다고 한다.
이 외에도, Radial Basis Function이나 Spectral Method 등을 이용해서 최적화를 하는 방법도 있다고 한다. 연구가 활발하게 이루어지면서 다양한 방법이 만들어지는 듯하다.
Reference
"Feature Selection", Wikipedia, en.wikipedia.org/wiki/Feature_selection
"Bayesian Optimization", Wikipedia, en.wikipedia.org/wiki/Bayesian_optimization
Snoek, J., Larochelle, H., & Adams, R. P. (2012). Practical bayesian optimization of machine learning algorithms. arXiv preprint arXiv:1206.2944.
사실 Hyperparameter Optimization을 한다고 하면, 경험이 많지는 않지만 Random Search나, Bayesian Optimization을 사용하는 경우가 많으며, 이들이 어떤 원리로 굴러가는 지를 어렴풋이 알고는 있었다. 그럼에도 불구하고 이러한 방법들을 각잡고 공부하는 과정에서 다시 확인하며 시야가 넓어진다는 점은 정말 좋은 것 같다.
'Statistics' 카테고리의 다른 글
Edwith _ 최성준님의 Bayesian Deep Learning (일부 수강) (0) 2022.01.25 Naive Bayes Classification _ 나이브 베이즈 분류 (0) 2021.01.01