-
Edwith _ 최성준님의 Bayesian Deep Learning (일부 수강)Statistics 2022. 1. 25. 00:00
Gal, Y., & Ghahramani, Z. (2016, June). Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning (pp. 1050-1059). PMLR.
이미지에 대한 준지도 학습에 대해서 공부하던 중, 준지도 학습, 특히 self training에서 unlabeled 데이터를 어떻게 학습시킬까에 대한 고민을 하게 되었다. 무식하게 다 때려 박아서 재학습을 진행하는 것보다는, 재학습 시 모델이 잘 알 수 있는 자료에 가까운 것들부터 배우는 것이 맞을 것이다. true label과 최대한 동일해야 하기 때문이다.
그런데 데이터가 수 백개, 수 천개 이상이 되는 순간부터는 현실적으로 true label인지 아닌지 맞출 수가 없다(사실상 true label인지 아닌지 알아본다는 건 사람이 data labeling을 하여 사용한다는 것인데, 이러면 준지도 학습도 아니다). 때문에 준지도 학습을 위해서는, 100% 맞는 label을 줄 순 없어도 좋은 labeling이 가능한 unlabeled 데이터를 찾는 것이 중요하다고 생각했다.
처음에는 sigmoid의 출력값이 큰 데이터들만 모으면 될 거라 생각했다. 근데, sigmoid가 정말로 labeling의 정확도와 관련이 있을까? 결론은 아니라는 것이다. 고양이를 input으로 삼아 품종을 분류하는 모델에 강아지를 집어넣었을 때, sigmoid가 labeling의 정확도를 나타내려면 "어떤 품종인지 잘 모르겠다"라는 결론을 얻어야 한다. 그런데 sigmoid는 어떻게든 분류를 진행해버린다.
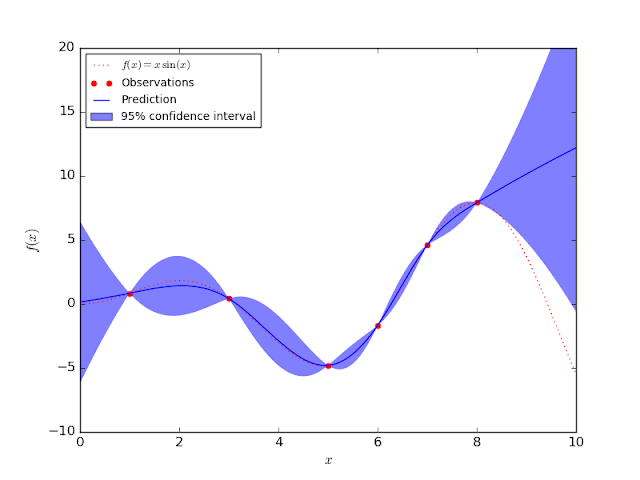
결과의 분포를 알면 CI에 대한 정의가 가능해진다. 그럼 어떻게 output의 confidence를 측정할 수 있을까? 준지도에 대한 연구가 많이 진행되어 방법은 여러가지가 있겠지만, 나는 bayesian model로 접근을 해보려 했다. output이 값이 아니라 분포로 나오도록 유도하는 것이다. 만약, output의 분산이 크다면, 매 예측마다 결과가 달라진다는 것이며, 이는 넓은 CI와 높은 uncertainty라는 중요한 정보를 알려준다!
NN은 이게 어렵다. Bayesian Neural Network의 구현이 쉽지 않다는 것이다. 하지만 이것을, 우리가 흔히 사용하는 Dropout을 이용해서 구현하는 방법을 제안한 것이 위 논문이다.
근데 너무 어려웠다. 그래서 Edwith의 강의 중 해당 논문과 관련 배경 지식을 다루는 강의가 있어 듣고, 필기해보았다.










 012345678910
012345678910
한번에 이해하려는 건방진 생각은 안했지만, 생각보다 어려워서 받아 적어 놓고도 이해가 쉽지 않았다. 관련해서 랩미팅을 위해 내 공부 내용과 연결하는 PPT도 만드는 중인데, PPT를 만들다가 선배와 이야기를 (정말 잠깐) 했는데, 그 부분에서 감사하게도 약간 이해가 가지 않는 부분에 대해서 해결된 듯한 느낌이 있어 그나마 다행이라고 생각한다.
'Statistics' 카테고리의 다른 글
Hyperparameter optimization _ 하이퍼파라미터 최적화 (0) 2021.02.25 Naive Bayes Classification _ 나이브 베이즈 분류 (0) 2021.01.01